Hello, I am Ziraddin
I build production-oriented machine learning systems that transform research ideas into scalable, reliable applications. My work focuses on designing end-to-end ML platforms, including modular Retrieval-Augmented Generation (RAG) pipelines, computer vision models, and LLM-based applications with clear architectural separation across ingestion, feature processing, retrieval, inference, evaluation, and monitoring components.
Across projects, I develop reproducible ML workflows supported by experiment tracking with MLflow, containerized model services using FastAPI and Docker, and scalable deployments orchestrated with Kubernetes. CI/CD pipelines automate testing, packaging, and model delivery, while monitoring stacks such as Prometheus, Grafana, and Evidently AI provide visibility into system behavior and model performance in production environments.
Tech Stack
Core tools and technologies I use regularly
Latest Projects
See all →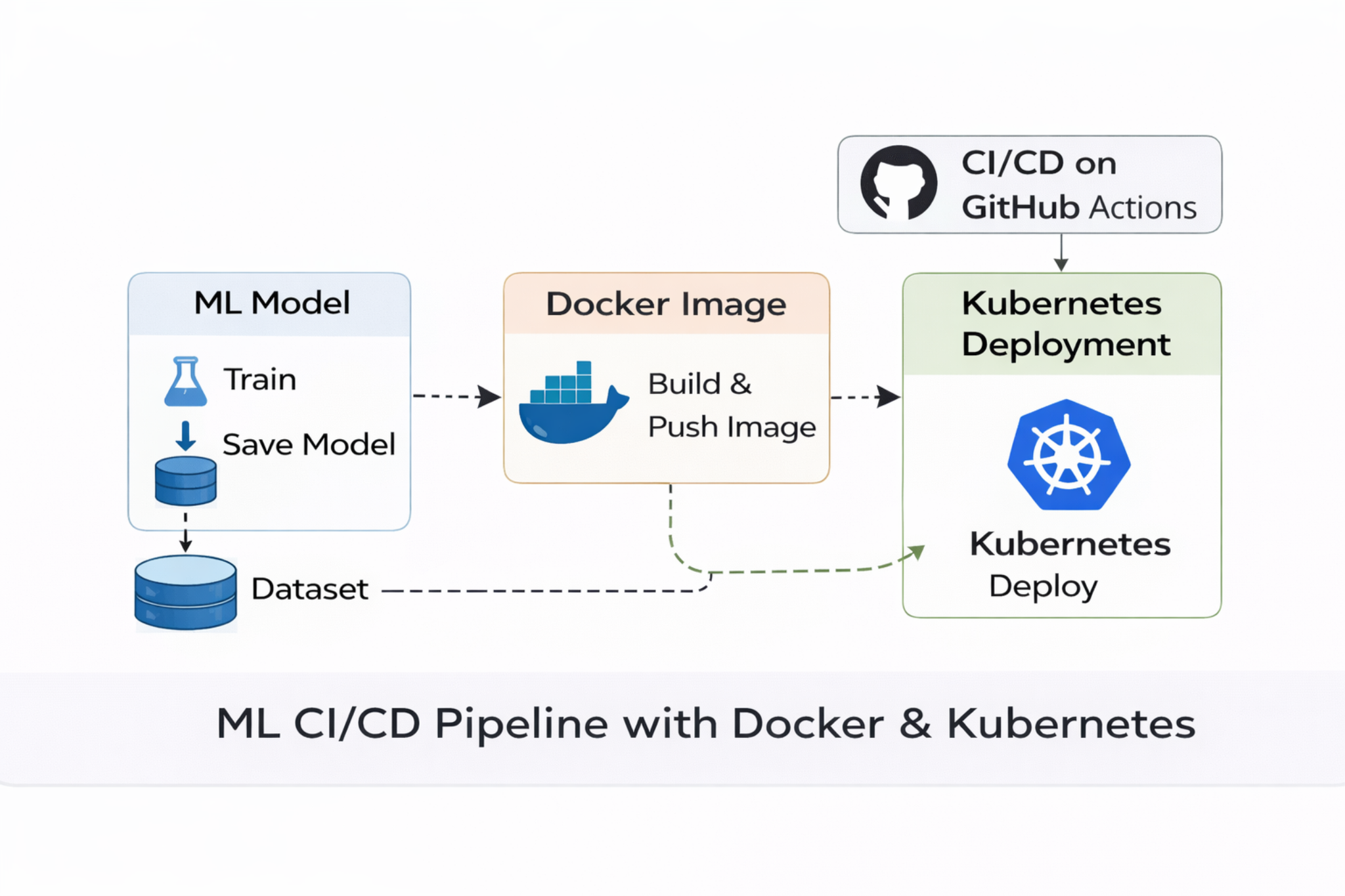
Cloud-Native ML Deployment Architecture (Docker, Registry, GKE)
Building and deploying a machine learning model to predict diabetes risk using patient health data, packaging the model in a Docker container, exposing it through a FastAPI service, and deploying it to Kubernetes with an automated CI/CD pipeline.
Engineering a Production-Grade LLM Tutor for Structured Mathematics Reasoning
Engineering a production-grade LLM-powered IGCSE mathematics tutoring platform by integrating a React frontend, a Django backend, and PostgreSQL persistence, orchestrating controlled model inference with structured prompt governance, containerizing the system with Docker, and implementing monitoring
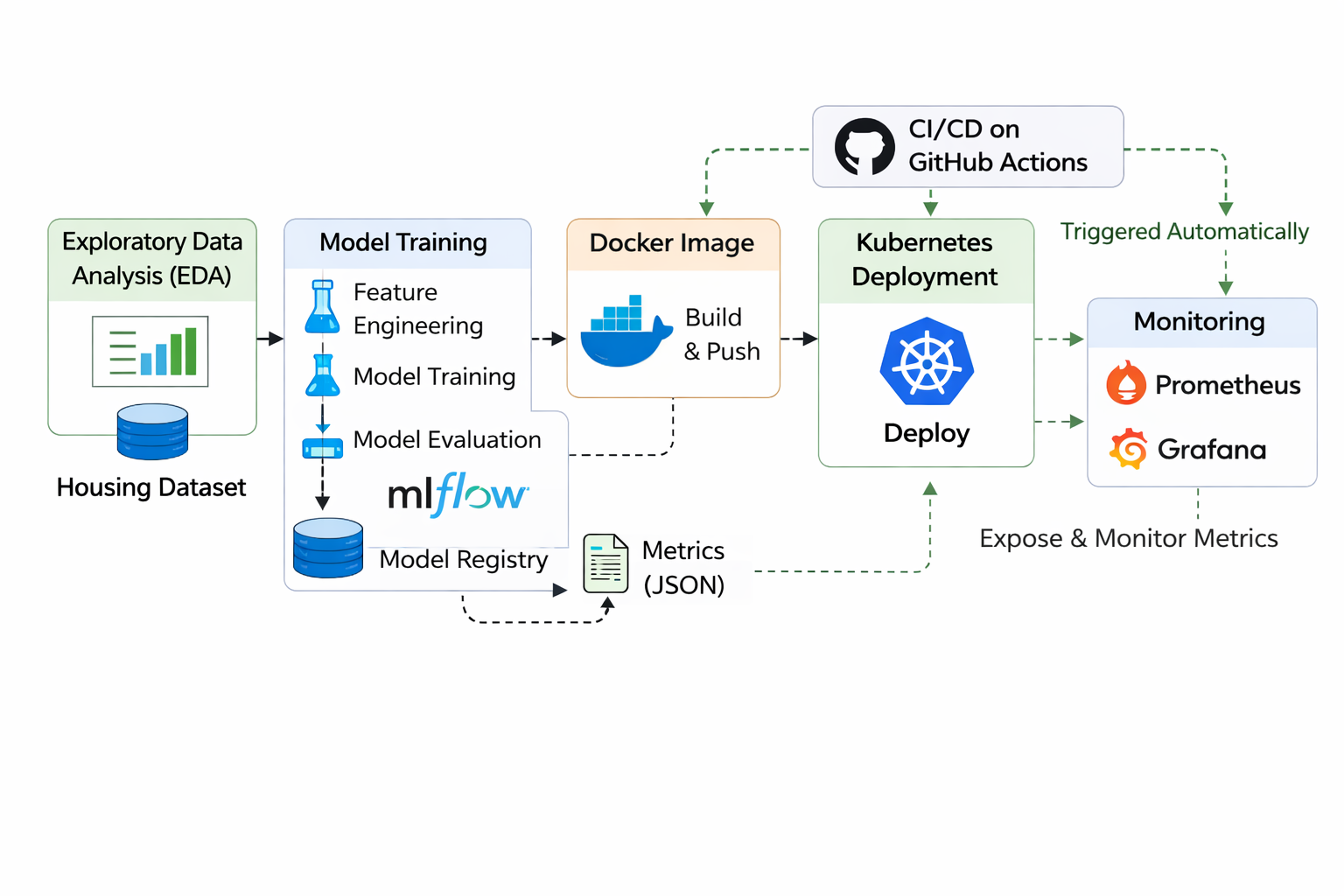
Operationalizing Tabular ML: CI/CD, Docker, Kubernetes, Observability
Building a regression pipeline to predict housing prices using the California housing dataset, applying preprocessing and feature engineering with scikit-learn, tracking experiments with MLflow, serving predictions through a FastAPI API, containerizing the service with Docker, monitoring it using Pr
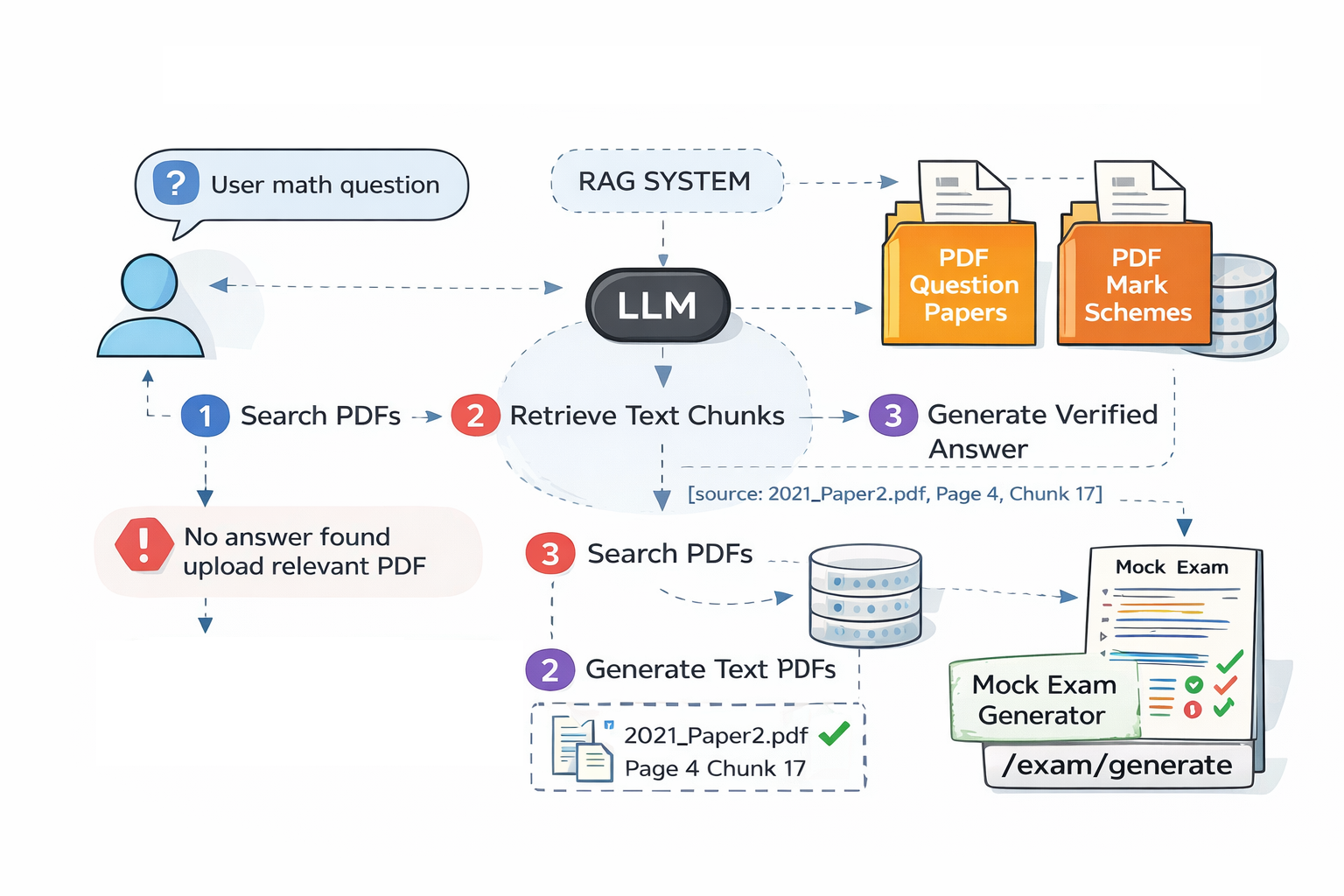
Building a RAG Question Answering System Using LLM models and Vector Databases
Developing a retrieval-augmented question answering system over 7,500+ pages of Cambridge IGCSE Mathematics past papers by ingesting and chunking exam PDFs, generating embeddings and indexing them in a vector database, retrieving relevant context through semantic search, and generating step-by-step
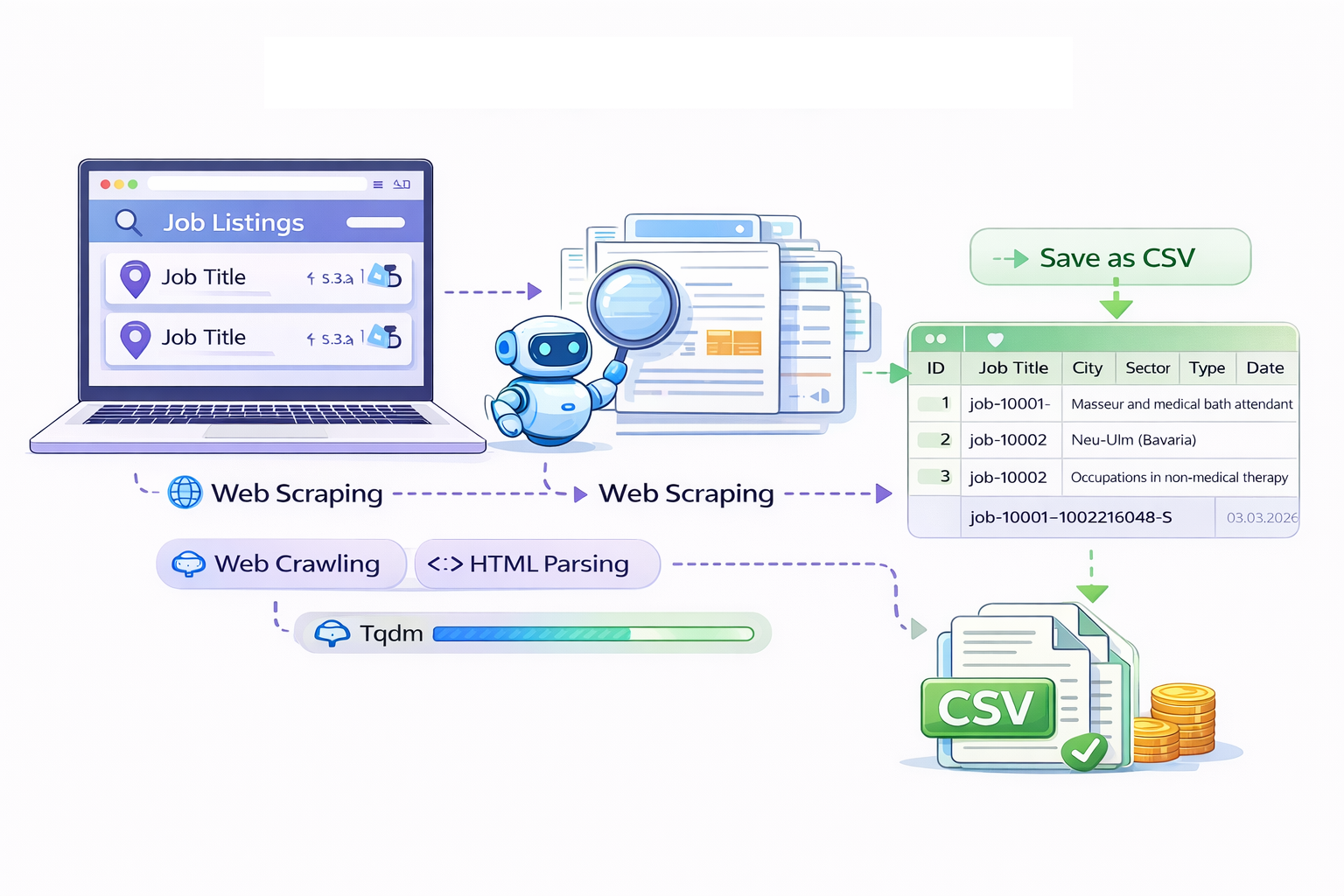
Web Scraping and Analysis of Job Market Data in Germany
Collecting and structuring 22K+ job listings from a German job portal using a Python web scraping pipeline, enabling large-scale analysis of sector demand, job distribution, and geographic employment patterns across Germany.

Applied Data Science: Analytics, Visualization, and Machine Learning
Projects exploring data analysis, machine learning, and interactive visualization using R. The work focuses on analyzing film industry trends, streaming platform datasets, and healthcare data to uncover patterns and meaningful insights.