This website brings together projects in data science, machine learning, and modern AI systems. It is built around one main idea: analytical thinking becomes powerful when it turns into something useful. The site is still new and growing, but the direction is clear. I was not pulled into machine learning because it sounded trendy. I was pulled into it because it matches the way I already think. Here, you will find work that starts with messy data and moves toward clear insight, reliable models, and practical solutions. Some projects focus on exploration and statistical reasoning. Some focus on prediction, classification, and model performance. Others move closer to real-world systems where the goal is not just to make something work once, but to make it understandable, testable, and useful. I also plan to grow beyond written projects, with future YouTube content where I can explain concepts in a more visual and practical way.
Disclaimer: website and me is still growing. We do not pretending everything is perfect; it is about building, learning, improving, and showing the process honestly.
Thanks!
Tech Stack
Core tools and technologies I use regularly
Latest Projects
See all →
The Ocean’s Memory: Regression prediction on Ocean Temperature Using over 60 Years of CalCOFI Environmental Data
Built a leakage-safe regression pipeline on nearly one million CalCOFI oceanographic records, using selected environmental and spatial features to predict Pacific Ocean temperature across over 60 years of observations.

Animal Classification with Regularized Models and Compact Ensembles
Created a mini-classifier to separate zoo animals into biological groups using features such as hair, feathers, milk, eggs, fins, legs, and aquatic behavior. Regularized models and compact ensemble methods were compared to build a simple, controlled classification pipeline.

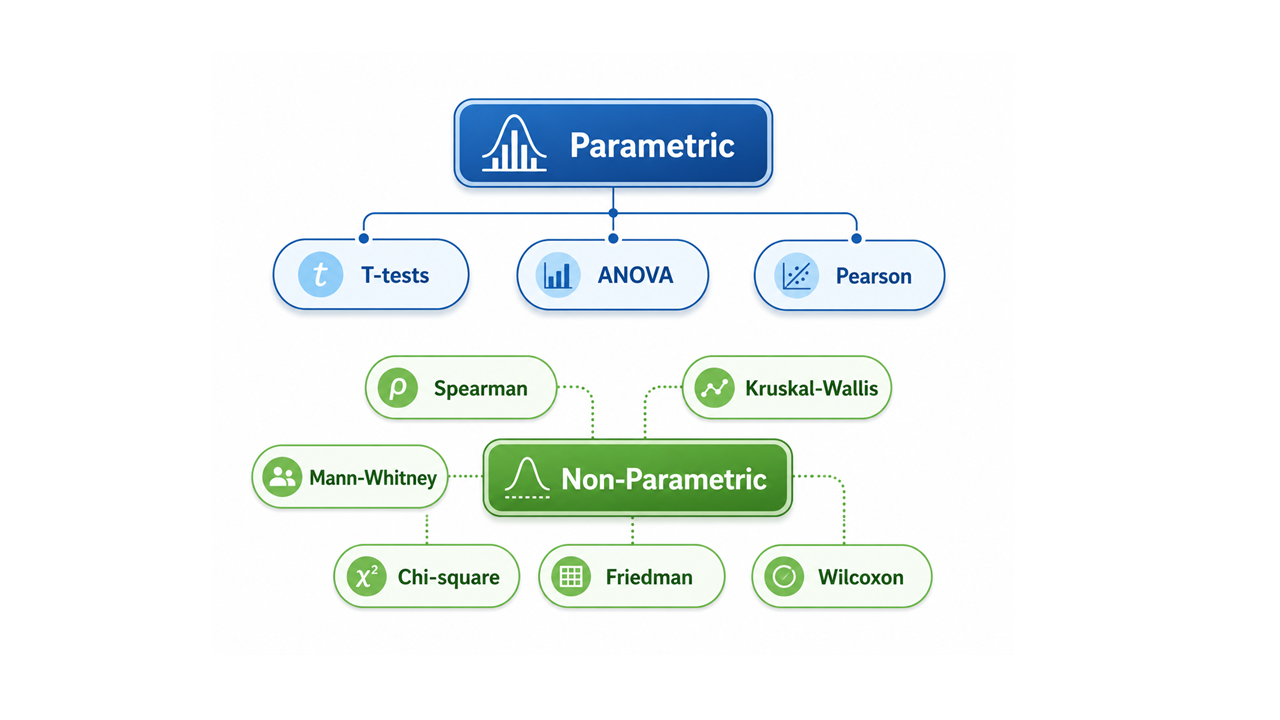
Parametric and Non-Parametric statistical tests
Built a comprehensive statistical testing workflow covering both parametric and non-parametric methods. The project demonstrates how to choose and apply appropriate tests such as t-test, ANOVA, Mann-Whitney U, Kruskal-Wallis, Wilcoxon, Chi-square, Pearson, and Spearman using Python and SciPy.

Ensemble Learning for Penguin Species Multiclass Classification Using Morphological and Ecological Features
Built a multiclass ML pipeline to classify penguin species using body measurements and ecological features. Compared baseline and ensemble models with cross-validation and tuning to select the best model.
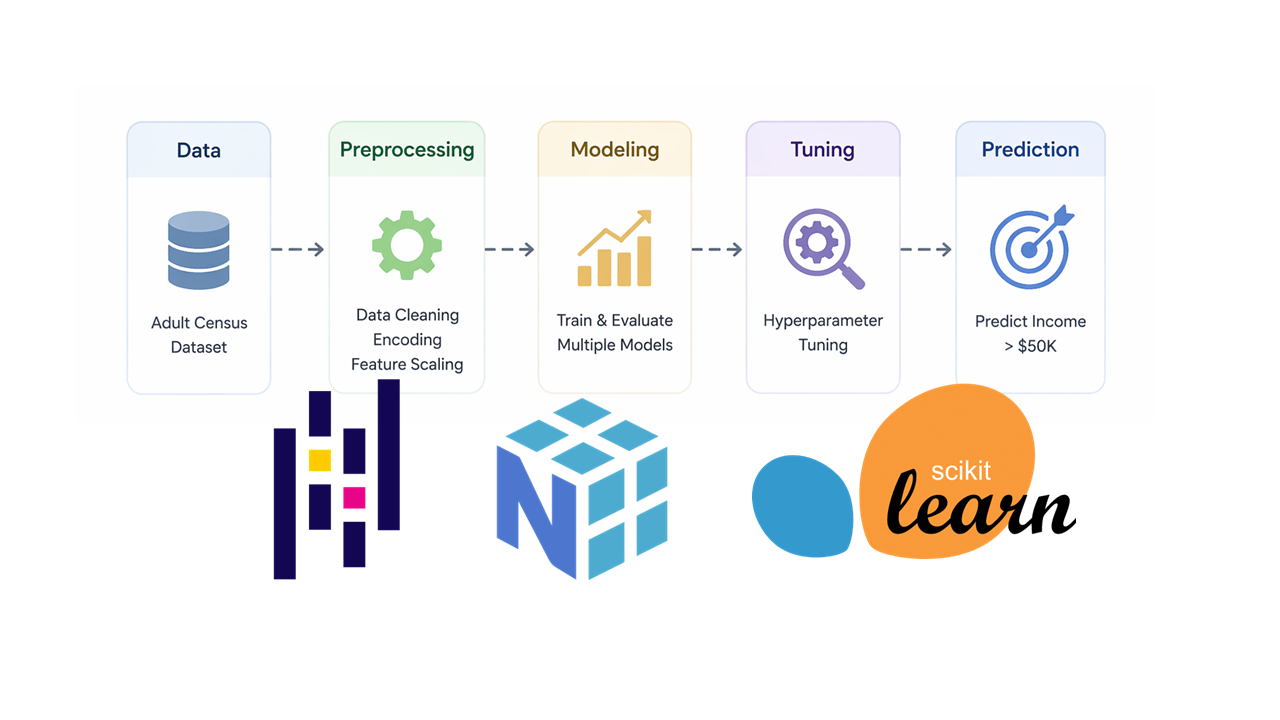
End-to-End Census Income Classification with EDA and Hyperparameter Tuning
Built an end-to-end machine learning pipeline on the Adult Census Income dataset to predict whether an individual earns above or below $50K per year. The project covers data cleaning, EDA, preprocessing, model comparison, hyperparameter tuning, and final evaluation with Gradient Boosting as the best