Project Status — Ongoing Development
This project is currently under active development.
Continual Learning on Permuted MNIST (PyTorch)
Overview
This project implements an end-to-end continual learning (CL) benchmark designed to study catastrophic forgetting in neural networks.
A single model is trained sequentially on multiple tasks derived from the MNIST dataset, where each task applies a fixed random pixel permutation while preserving digit labels.
The system evaluates three representative learning strategies:
- Naive Sequential Training
- Experience Replay (ER)
- Elastic Weight Consolidation (EWC)
All methods share the same architecture and training budget, enabling a controlled comparison of stability vs. plasticity in continual learning systems.
Problem Setup
Given an image–label pair $(x, y)$ where $x \in \mathbb{R}^{28\times28}$ and $y \in {0,\dots,9}$,
the flattened vector $x \in \mathbb{R}^{784}$ is transformed using a task-specific permutation:
$$ \tilde{x}t = P{\pi_t} x $$
Ten different permutations create a sequence of learning tasks:
$$ {D_1, D_2, \dots, D_{10}} $$
The model must learn each new task without forgetting the previous ones.
Model
A shared multi-layer perceptron is used for all experiments:
$$ h_1 = \mathrm{ReLU}(W_1 x + b_1) $$
$$ h_2 = \mathrm{ReLU}(W_2 h_1 + b_2) $$
$$ z = W_3 h_2 + b_3 $$
$$ \hat{y} = \arg\max_k z_k $$
Architecture: 784 → 256 → 256 → 10
Training uses cross-entropy loss:
$$ \mathcal{L}{CE} = -\frac{1}{|B|} \sum{(x,y)\in B} \log p_\theta(y|x) $$
Continual Learning Methods
1. Naive Sequential Training
The model is fine-tuned on each task using only current data:
$$ \theta_t = \arg\min_\theta \mathbb{E}{(x,y)\sim D_t}[\mathcal{L}{CE}(f_\theta(x),y)] $$
This baseline typically leads to severe catastrophic forgetting.
2. Experience Replay (ER)
A memory buffer stores past samples and mixes them with current batches:
$$ \theta_t = \arg\min_\theta \mathbb{E}{(x,y)\sim D_t \cup M}[\mathcal{L}{CE}(f_\theta(x),y)] $$
The buffer is maintained via reservoir sampling.
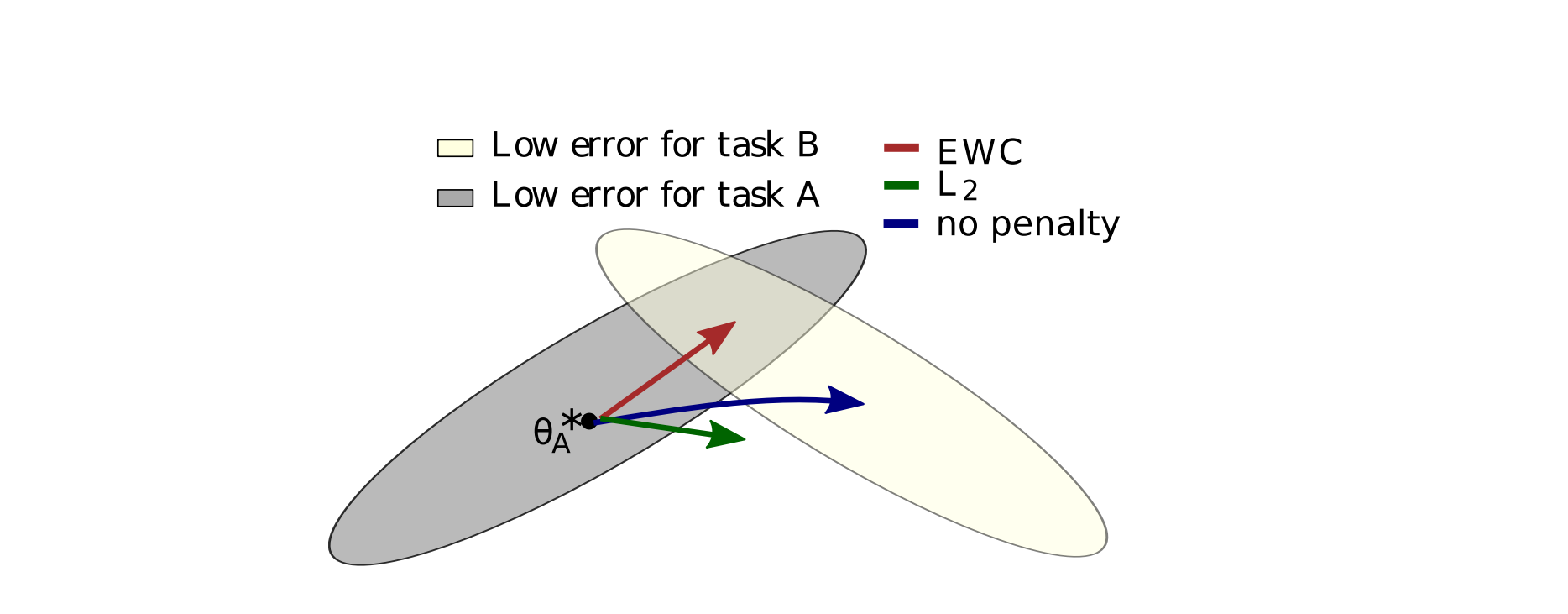
3. Elastic Weight Consolidation (EWC)
EWC preserves important parameters by penalizing deviation from previous tasks:
$$ \mathcal{L}{EWC} = \mathcal{L}{CE} + \frac{\lambda}{2}\sum_i F_i(\theta_i - \theta_i^*)^2 $$
Where:
- $F_i$ — Fisher information (parameter importance)
- $\theta_i^*$ — parameter snapshot after previous tasks
- $\lambda$ — stability–plasticity trade-off coefficient
Evaluation Metrics
After training task $t$, performance is measured on all tasks:
$$ A_{t,i} = \mathrm{Accuracy}(\theta_t, D_i^{test}) $$
Final Average Accuracy
$$ AA = \frac{1}{T} \sum_{i=1}^{T} A_{T,i} $$
Backward Transfer (Forgetting)
$$ BWT = \frac{1}{|{i<j}|}\sum_{i<j}(A_{j,i}-A_{i,i}) $$
Per-Task Forgetting
$$ F_i = \max_{t\ge i} A_{t,i} - A_{T,i} $$
Results
| Method | Final Avg Accuracy | BWT | Avg Forgetting |
|---|---|---|---|
| Naive | 0.5103 | -0.3692 | 0.4608 |
| ER | 0.9281 | -0.0306 | 0.0434 |
| EWC | 0.9261 | -0.0287 | 0.0373 |
Naive training suffers severe forgetting, while ER and EWC maintain stable performance across all tasks.