NOTE: This post is under active revision. The system architecture, metrics, and deployment details are being refined to reflect the current production configuration.
This project implements an AI-driven IGCSE mathematics tutoring platform engineered as a structured web system rather than a conversational demo. The objective was to design a controlled, monitorable, and reproducible LLM-backed service that behaves predictably under load, exposes operational telemetry, and enforces pedagogical structure at the application layer instead of delegating responsibility entirely to the model. The system integrates a React frontend, a Django backend, PostgreSQL for persistence, Docker-based containerization, and a full observability stack powered by Prometheus and Grafana. The large language model functions as a computational dependency within a constrained inference boundary, not as the core architectural primitive.

The architecture was intentionally organized around separation of responsibilities so that each layer enforces deterministic control over its domain. The React interface is responsible solely for user interaction and structured rendering, while the Django application layer performs validation, prompt construction, inference orchestration, response normalization, metrics emission, and persistence. By ensuring that all model interaction occurs inside a controlled backend boundary, the system avoids the common anti-pattern of directly proxying user input to an external API without structural safeguards. This architectural decision ensures that model behavior remains inspectable, measurable, and bounded by application-level rules.
The tutoring logic does not depend on document retrieval pipelines, embedding indexes, or vector search mechanisms; instead, instructional consistency is achieved through disciplined prompt engineering and parameter governance. The model is constrained to operate within a strictly defined pedagogical context, where it must generate step-by-step IGCSE-level mathematical reasoning, avoid advanced shortcuts, and adhere to structured output formatting. Temperature settings are deliberately configured toward determinism in order to reduce variance across similar problem inputs, which sacrifices generative diversity in favor of reproducibility and student-facing clarity. This tradeoff reflects a systems-oriented philosophy in which predictability and correctness outweigh conversational creativity.

The backend, implemented using Django, was selected for its mature ORM, structured configuration model, and suitability for production environments requiring state persistence and operational introspection. Within the request lifecycle, input data is normalized and validated before prompt assembly occurs, after which token constraints are enforced to bound inference cost and latency. The response returned by the LLM is then post-processed to verify structural integrity before being persisted alongside metadata such as token usage, latency, and error indicators. By embedding control logic before and after inference, the application treats the model as a probabilistic computation engine operating within deterministic guardrails.
Operational visibility is achieved through instrumentation integrated directly into the backend. Metrics describing request throughput, latency distributions, error frequencies, and token consumption are exposed via an endpoint scraped by Prometheus, while dashboards constructed in Grafana provide time-series analysis of system behavior under real usage conditions. This observability layer transforms the tutoring service from a black-box AI application into a measurable distributed component, allowing latency percentiles, cost drift, and failure modes to be tracked without manual log inspection. Instead of reacting to failures retrospectively, the system enables proactive monitoring based on quantitative telemetry.
Persistence is handled through PostgreSQL rather than SQLite in order to avoid concurrency limitations and file-locking constraints that typically hinder production readiness. Each interaction is stored together with associated metadata, including prompt configuration, response content, token counts, latency measurements, and error flags, thereby enabling retrospective evaluation of model performance and system efficiency. This historical data layer makes it possible to analyze behavioral drift, assess cost trends, and audit response quality across time without re-executing inference.
Containerization was implemented through Docker to ensure environmental consistency across development and deployment stages. By encapsulating Django, PostgreSQL, Prometheus, and Grafana as isolated services within a reproducible container environment, the system achieves deterministic configuration management and dependency isolation. Environment variables are used for secret management and runtime configuration, thereby enabling separation between local development and production settings without code modification. This design reduces deployment friction and ensures that operational behavior remains consistent across environments.
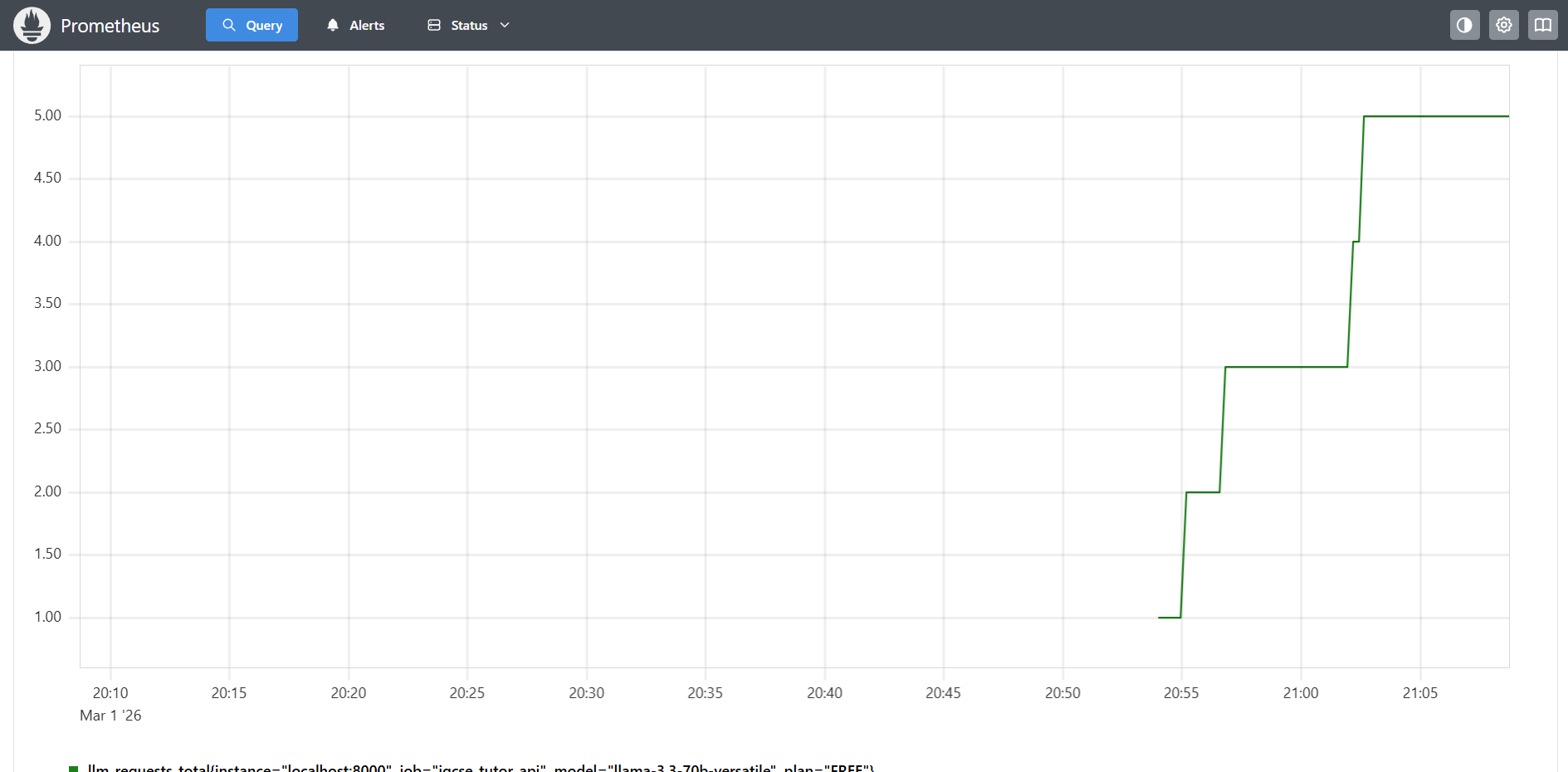
From a performance standpoint, the system maintains average response latencies in the low-second range under moderate concurrency, with percentile tracking performed via histogram metrics exported to Prometheus. Token consumption is monitored at request granularity, enabling cost estimation models to approximate daily operational expenditure based on real usage patterns. Error rates remain bounded primarily by upstream API instability rather than application-level faults, which are minimized through structured validation and bounded input constraints. By coupling token accounting with latency metrics, the system allows tradeoff evaluation between verbosity, cost, and responsiveness.
Several design decisions intentionally privilege engineering rigor over architectural novelty. The absence of retrieval subsystems simplifies operational complexity and reduces infrastructure overhead, while deterministic temperature control enhances instructional consistency. Backend-centric orchestration increases implementation effort but ensures reliability and auditability. Observability integration adds operational surface area but converts the application into a measurable service suitable for scaling and cost governance. Each of these decisions reflects an engineering bias toward controllability, transparency, and system integrity rather than experimentation.