View the full project on GitHub - will be available soon
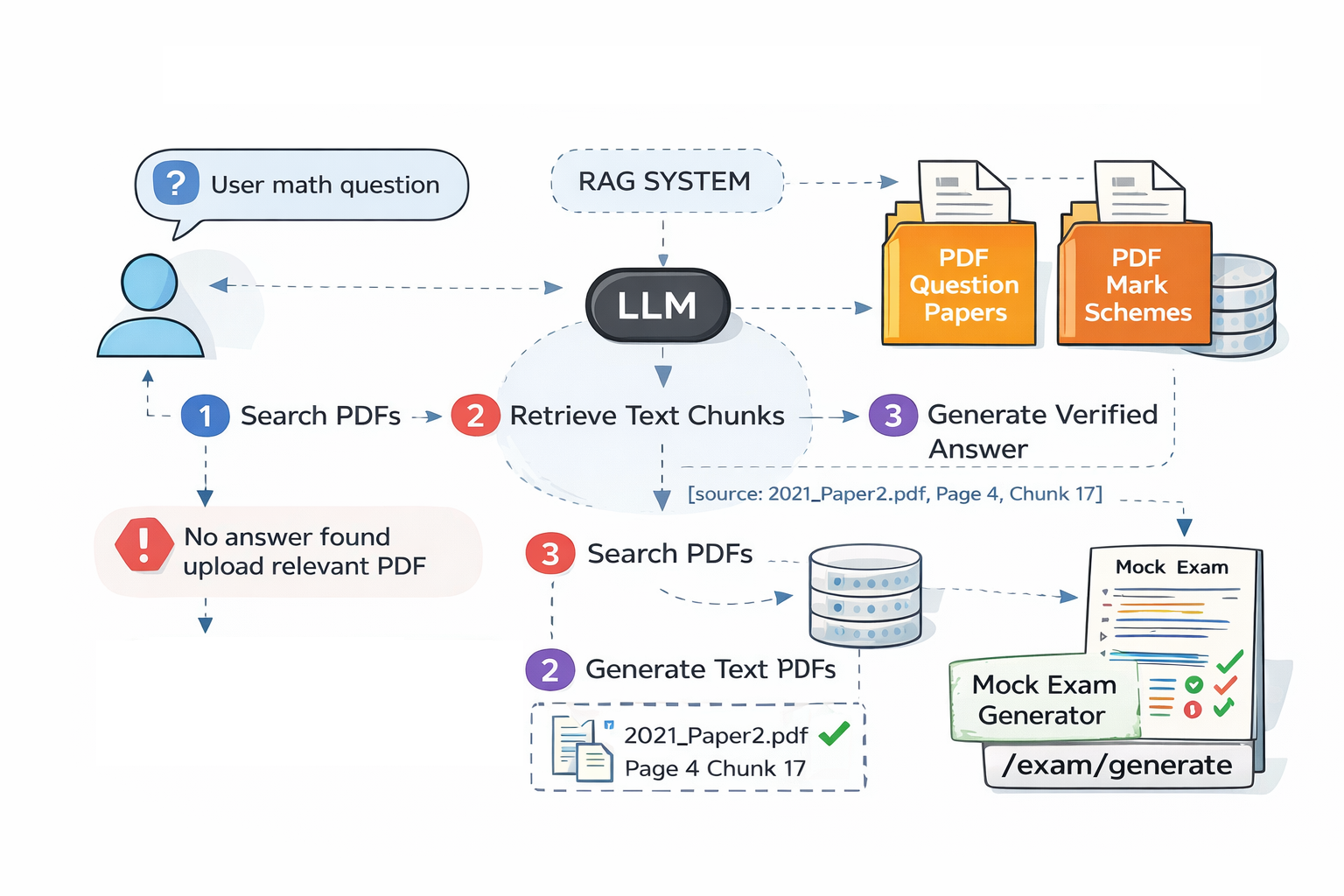
This project implements a Retrieval Augmented Generation (RAG) system designed to function as an AI tutor for Cambridge IGCSE Mathematics past papers. The system allows students to ask exam-style questions and receive structured, step-by-step solutions grounded strictly in official exam documents.
The knowledge base consists of more than 7,500 pages of Cambridge IGCSE Mathematics past papers and mark schemes spanning 2013–2025, representing over a decade of exam material. Rather than relying on the language model’s internal knowledge, the system retrieves relevant information directly from these documents and uses it as the basis for answer generation. This ensures that responses remain verifiable and aligned with official exam content.
Document Ingestion and Processing
The pipeline begins with a document ingestion stage where PDFs are loaded from the project’s data directory. The ingestion process is implemented in rag/ingest.py and uses PyMuPDF (fitz) to parse each document page-by-page.
During ingestion, metadata such as:
- exam year
- exam session (May/June, Feb/March, Oct/Nov)
- document type (question paper or mark scheme)
- paper number and variant
are extracted directly from the filename patterns used by Cambridge exam papers.
Once parsed, the text is split into smaller segments using LangChain’s RecursiveCharacterTextSplitter. In the current implementation the splitter uses:
- chunk_size = 1200 characters
- chunk_overlap = 200 characters
Each chunk is assigned metadata including:
source
page
chunk_id
Chunk IDs follow a structured format:
<filename>-p<page>-c<chunk_number>
For example:
0580_s21_qp_42.pdf-p4-c017
This structure later allows the system to generate precise citations.
Embedding and Vector Indexing
Once text chunks are created, they are converted into vector embeddings using the OpenAI embedding model
text-embedding-3-large
Embeddings are generated through the OpenAIEmbeddingClient implemented in rag/retrieval.py. The system supports both the OpenAI SDK and direct HTTP API requests as fallback.
The resulting embeddings are stored in a ChromaDB vector database. The Chroma collection used by the system is defined in configuration as:
igcse_math_past_papers
Each stored vector includes:
- embedding vector
- page content
- source filename
- page number
- chunk identifier
This indexed vector store forms the searchable knowledge base used by the RAG system.
Retrieval Pipeline
When a student submits a question, the system enters the retrieval stage of the RAG pipeline.
The user query is first embedded using the same embedding model used during ingestion. A semantic similarity search is then performed against the ChromaDB index.
The retriever configuration defined in config.py uses:
TOP_K = 6
FETCH_K = 24
USE_MMR = True
SCORE_THRESHOLD = 0.55
This means the system:
- retrieves up to 24 candidate chunks
- applies Max Marginal Relevance (MMR) to improve diversity
- selects the top 6 most relevant chunks as context
These retrieved chunks are then passed to the language model as the only allowed information source.
Prompt Engineering and LLM Interaction
The language model is accessed through the OpenAI API, using the model configured in the system settings:
gpt-5.2
The system uses a strict prompt template implemented in rag/llm.py. The instructions embedded in the prompt enforce grounded responses.
The prompt contains the following non-negotiable rules:
You are a Cambridge IGCSE Mathematics exam tutor.
NON-NEGOTIABLE RULES:
1) Use ONLY the provided PDF context chunks.
2) If the context does not contain enough information to answer, you MUST reply with exactly:
"I can’t find this in the provided IGCSE PDFs. Please upload the relevant paper/year or ask a question that matches the material."
3) Every factual claim or solution step MUST include citations in the exact format:
[source: <filename>, page: <page>, chunk: <chunk_id>]
4) Show exam-ready working: define variables, show algebra steps, and end with:
Answer: <final answer>
5) Do NOT use general knowledge. Do NOT invent missing numbers.
6) If a question is ambiguous, ask the minimum clarifying question, but still only using the context.
This prompt ensures the model performs grounded generation, meaning it can only generate answers based on retrieved evidence.
Answer Generation and Citation Enforcement
Once the prompt and retrieved context are assembled, the LLM generates the final response. Answers are formatted to resemble official exam mark schemes, including:
- algebraic steps
- reasoning explanations
- clearly stated final answer
Every step must include citations referencing the exact source chunk. The citation format enforced by the system is:
[source: <filename>, page: <page>, chunk: <chunk_id>]
This design provides full traceability, allowing users to verify exactly where the information originated in the exam documents.
API Architecture
The system backend is implemented using FastAPI, providing a lightweight API layer for interacting with the RAG pipeline.
Key components include:
rag/ingest.py → PDF ingestion and chunk generation
rag/retrieval.py → vector search and embedding handling
rag/llm.py → prompt construction and LLM calls
rag/exam.py → practice exam generation
rag/citations.py → citation formatting
The backend follows a modular service architecture similar to Django-style separation of concerns, where different modules handle ingestion, retrieval, generation, and evaluation independently.
The API exposes endpoints for:
- asking questions
- generating mock exams
- retrieving mark schemes
- grading answers
Evaluation Pipeline
To measure system performance, the project includes a retrieval evaluation framework implemented in:
scripts/evaluate.py
The evaluation script uses a dataset defined in:
data/golden_set.json
This dataset contains test questions with expected document references. The evaluation measures whether the retriever correctly identifies the relevant PDF chunks, providing insight into retrieval accuracy and RAG effectiveness.
Logging and Observability
The system also records query logs in:
data/logs/requests.jsonl
Each entry includes:
- user query
- retrieved chunks
- generated response
These logs can later be used to analyze model behavior and improve retrieval quality.
Future Development Directions
Several improvements could further extend the system:
1. Retrieval Optimization
Hybrid retrieval combining:
- dense vector search
- BM25 keyword search
to improve recall for exam questions.
2. Improved Chunking
Semantic chunking strategies could replace fixed character-based chunking to better align with question boundaries.
3. Answer Validation
Automatic comparison between generated answers and official mark schemes to evaluate correctness.
4. Model Fine-Tuning
Fine-tuning a smaller LLM specifically on exam solutions to improve mathematical reasoning.
5. Deployment and MLOps
Adding containerization, monitoring, and CI/CD pipelines to support production-scale deployment.
Summary
This project demonstrates a complete end-to-end RAG architecture for building a knowledge-grounded AI tutor. By combining document ingestion, embedding generation, vector indexing, semantic retrieval, prompt engineering, and LLM-based generation, the system provides accurate exam-style explanations derived directly from more than a decade of Cambridge IGCSE Mathematics past papers.