Building a Self-Healing MLOps System — From Dataset to Autonomous Model Lifecycle
Modern machine learning projects often stop at training a model and exposing an endpoint. In real production environments, that is only the beginning.
A deployed model must survive changing user behavior, infrastructure load, and data distribution shifts. The goal of this project was to build a system where a model is not only deployed — but continuously observed, evaluated, and automatically improved.
This article explains how a complete end-to-end autonomous MLOps system was designed and implemented.
1. The Problem With Typical ML Projects
Most ML repositories follow this lifecycle:
load data → train model → save model → build API
After deployment, the model silently degrades as real-world data changes. No alerts. No retraining. No guarantees.
In production, a model must answer three continuous questions:
- Is the service healthy?
- Is the machine overloaded?
- Is the model still correct?
This project was built to answer all three — automatically.
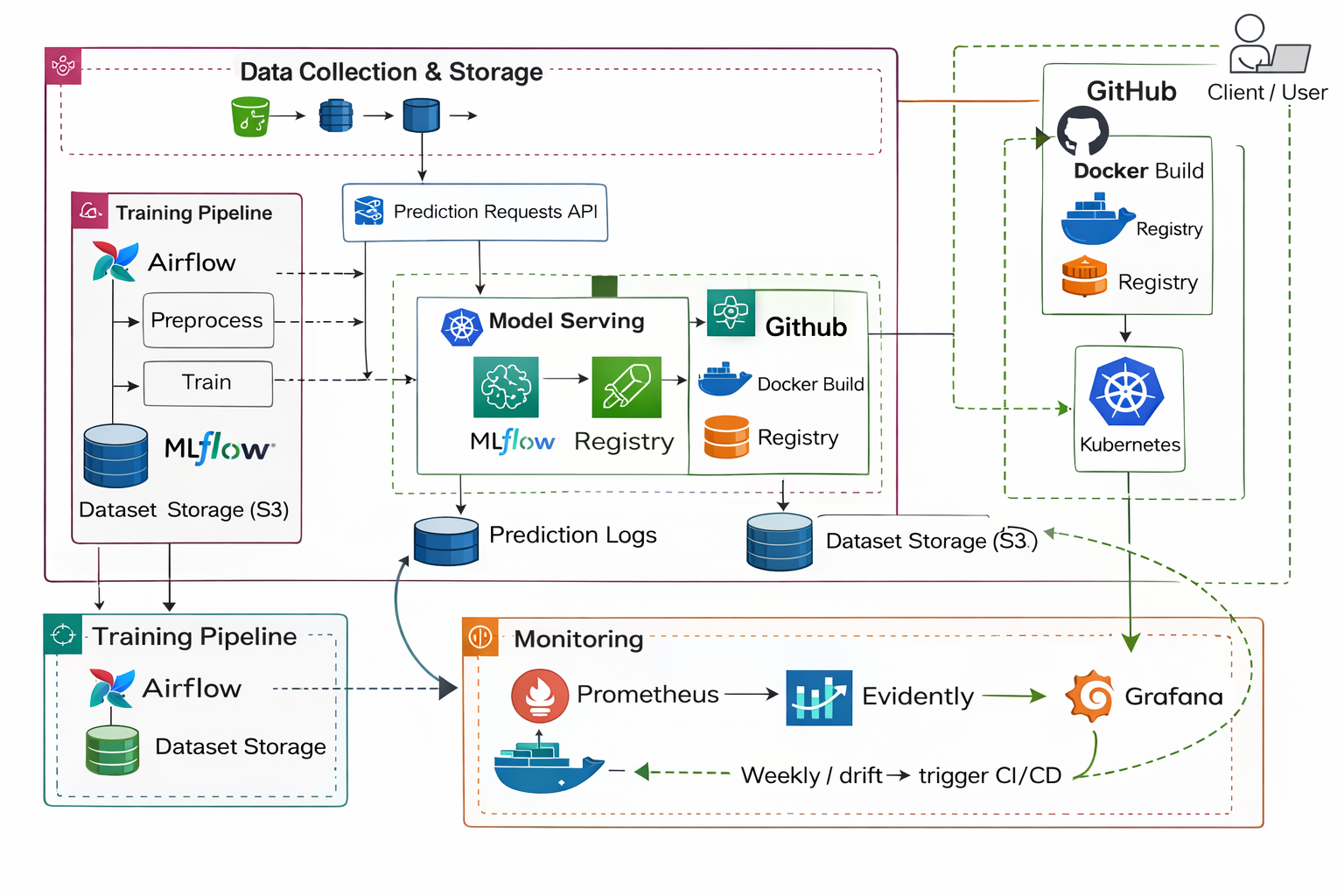
2. Automated Training Pipeline
The system begins with a generic dataset ingestion engine.
Instead of hardcoding preprocessing logic, the pipeline:
- detects target column automatically
- identifies categorical vs numeric features
- validates schema
- splits dataset
- trains multiple algorithms
- compares evaluation metrics
- selects the best model
Supported training types:
- Linear / Ridge
- Random Forest
- Gradient Boosting
Artifacts produced:
schema.json
feature_statistics.json
metrics.json
leaderboard.json
model.pkl
At this stage the project already behaves like an experiment tracking system rather than a notebook.
3. Model Registry & Versioning
Rather than replacing models, each training run creates a versioned artifact:
registry/
├── models/
│ ├── v0001/
│ ├── v0002/
│ └── ...
└── production.json
The service never loads “latest”. It loads the explicitly approved production model.
This mimics real ML lifecycle tools (MLflow / SageMaker) but implemented locally.
4. Production Inference Service
The model is exposed through a FastAPI application:
Endpoints
/predict
/health
/model_info
/metrics
Capabilities:
- batch inference
- schema validation
- dynamic model loading
- prediction logging
- Prometheus instrumentation
The model is now a continuously running system — not a script.
5. Containerized Deployment
The system runs as a full production-style stack:
API Service
Monitoring Worker
Prometheus
Grafana
Node Exporter
Docker Compose reproduces a real deployment environment locally.
This allows testing behavior under realistic runtime conditions.
6. Service Observability (Prometheus + Grafana)
Prometheus scrapes live runtime metrics:
- request throughput
- latency (p95)
- error rate
- prediction volume
Grafana visualizes service behavior in real time.
This answers:
Is the service responsive and stable?
7. Infrastructure Monitoring (Node Exporter)
Service health alone is insufficient. Performance issues may originate from hardware pressure.
Node Exporter provides system telemetry:
- CPU usage
- memory usage
- disk IO
- network traffic
- system load
This answers:
Is the machine causing model performance issues?
8. ML Monitoring (Evidently)
Even with perfect infrastructure, the model itself can silently fail.
A monitoring worker continuously analyzes production predictions:
- feature distribution shift
- data drift
- prediction drift
Reports are generated automatically:
reports/data_drift_timestamp.html
This answers:
Are real users different from training data?
9. Decision Engine
The system does not retrain blindly.
Rules:
IF drift small → keep model
IF drift large → trigger retraining
This prevents unnecessary retraining and preserves stability.
10. Continuous Retraining Loop
When drift crosses threshold:
- Collect recent production data
- Train candidate model
- Compare against current production model
- Promote only if performance improves
- API automatically serves new model version
No restart required.
The model evolves while the service remains live.
Final Lifecycle
The project implements the full operational ML lifecycle:
DATA
→ TRAIN
→ REGISTER
→ SERVE
→ OBSERVE (system)
→ OBSERVE (ML)
→ DECIDE
→ RETRAIN
→ REDEPLOY
What This Project Demonstrates
This system combines three disciplines:
Machine Learning
Model training, validation, evaluation
Software Engineering
APIs, containers, service reliability
MLOps
Monitoring, drift detection, automated lifecycle
Most ML projects end after deployment.
This project ensures the model stays correct after deployment.
Conclusion
The objective was not to build a model. The objective was to build a model that takes care of itself.
A real production ML system must:
- detect when it becomes outdated
- decide whether to retrain
- upgrade safely without downtime
This repository demonstrates exactly that — a self-healing machine learning service.