View the full project on GitHub
The project demonstrates a complete end-to-end machine learning deployment workflow using modern MLOps practices. The goal is to move a trained machine learning model from development into a production-ready environment that can serve predictions through a scalable and automated infrastructure.
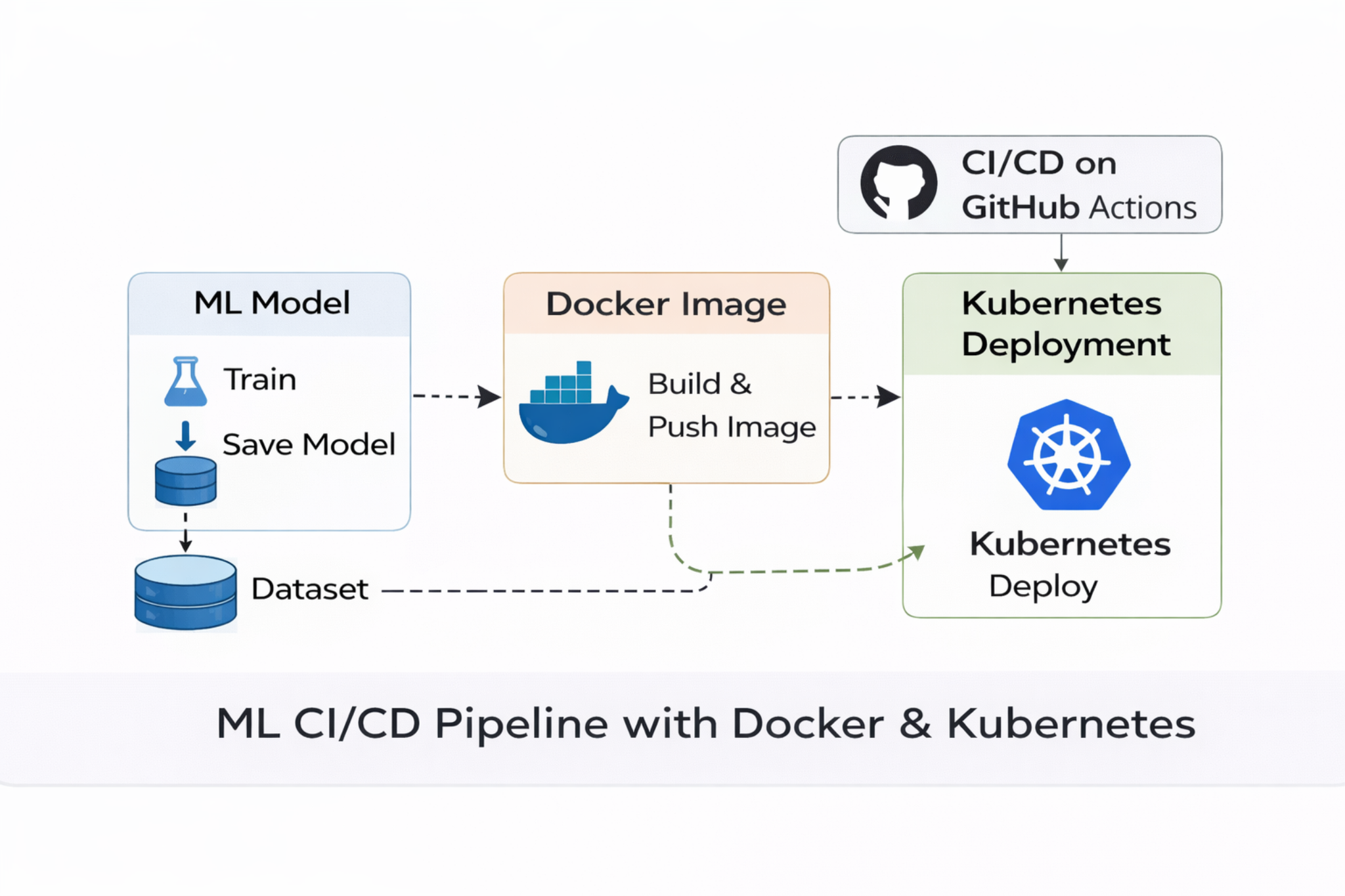
The workflow begins with training a classification model using the diabetes dataset. The model pipeline includes data preprocessing, feature scaling, and model training using scikit-learn. After evaluating multiple models, the best performing model is serialized and stored as a reusable artifact. This artifact becomes the core component used for inference in the deployed application.
To expose the trained model as a service, a lightweight REST API is built using FastAPI. The API accepts structured JSON input representing patient health metrics such as glucose levels, BMI, and age, and returns a prediction indicating diabetes risk. This API design enables the model to be integrated into other systems, applications, or dashboards that require real-time predictions.
The entire application is then containerized using Docker. Docker packages the Python runtime, application code, dependencies, and trained model artifact into a portable container image. Containerization ensures the application behaves consistently across development, testing, and production environments. The Docker image is built locally and then published to Docker Hub, making it accessible for deployment across distributed infrastructure.
Once the container image is available in the registry, the application is deployed to a Kubernetes cluster. Kubernetes orchestrates the deployment by creating and managing multiple application pods. These pods run the containerized ML service and ensure high availability. Kubernetes also provides a service layer that exposes the application endpoint and handles network routing between clients and the running containers.
To make the deployment process reproducible and automated, a CI/CD pipeline is implemented using GitHub Actions. The pipeline is triggered automatically whenever new changes are pushed to the repository. It performs several steps: checking out the codebase, building a fresh Docker image, authenticating with Docker Hub, pushing the updated image to the registry, and applying Kubernetes deployment updates. This automated workflow ensures that new model versions or application updates can be deployed quickly and reliably.
Through this project, several important MLOps concepts are demonstrated, including containerization, infrastructure orchestration, automated deployment pipelines, and scalable model serving. By combining Docker, Kubernetes, and CI/CD automation, the system provides a reproducible and production-oriented approach to deploying machine learning applications.
This architecture reflects common industry practices for machine learning systems operating in cloud environments, where models must be delivered as reliable services capable of scaling with demand while maintaining consistent deployment and monitoring processes.