View the full project on GitHub
House price prediction has always been one of the very first project for regression tasks, due to its many features. Here, we go ahead and add modern ML practices to the regression task and trying to fully develop pipeline. The main objective is to predict housing prices using a traditional machine learning model while demonstrating how models evolve from experimentation to a production-ready system.
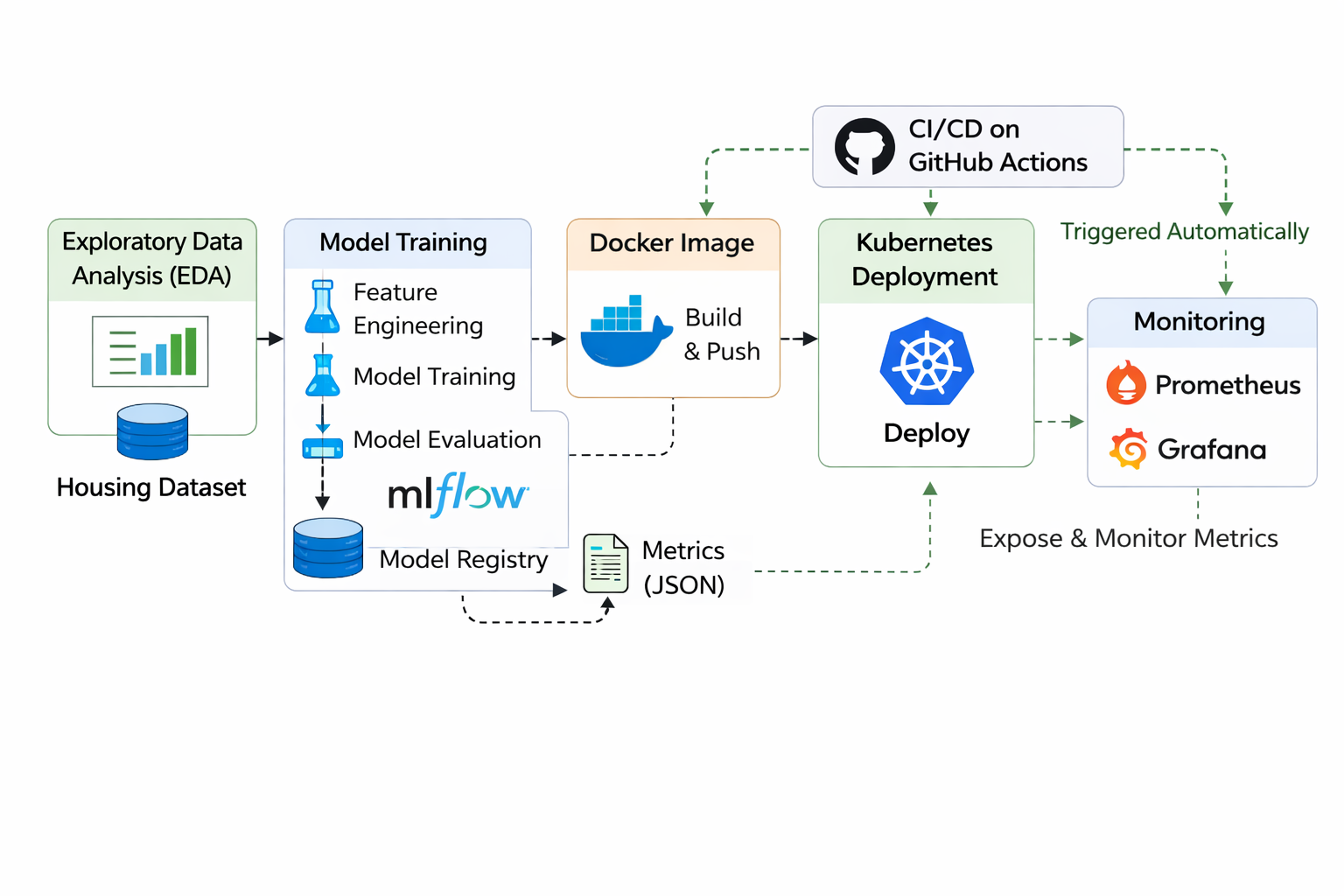
Work begins with exploratory data analysis (EDA) using the California housing dataset. During this stage, statistical summaries and visualizations are used to examine feature distributions, identify correlations, and detect possible data quality issues. Understanding these patterns early helps ensure that the training process is built on reliable and well-interpreted data.
Following the analysis phase, a training pipeline is developed using scikit-learn. The pipeline handles several preprocessing tasks, including missing value treatment, feature scaling, categorical encoding, and feature engineering. A Random Forest regression model is trained within this pipeline so that the same preprocessing steps are applied consistently during both training and inference.
Reproducibility and experiment tracking are handled through MLflow. Each training run records parameters, evaluation metrics, and artifacts such as trained models and results. Model versions are also stored in a local registry, making it easier to track different model iterations and manage deployments.
Once training is complete, the model is stored as a versioned artifact and served through a FastAPI application. The API exposes endpoints where users can submit housing features and receive predicted price estimates in real time. This turns the trained model into a usable prediction service that other systems can integrate with.
To ensure consistent execution across environments, the service is packaged inside a Docker container. The container bundles the API, trained model, and required dependencies, allowing the application to run reliably regardless of the deployment environment.
Basic monitoring capabilities are included as well. The FastAPI service exposes metrics that Prometheus can collect, providing insights such as request rates and response latency. These metrics are then visualized in Grafana dashboards, helping track the health and performance of the deployed service.
For scalable deployment, Kubernetes manifests are provided to run the API container within a cluster. Kubernetes handles pod management, scaling, and load balancing, allowing the service to operate reliably under production workloads.
Deployment is automated through a CI/CD pipeline built with GitHub Actions. When new code is pushed to the repository, the workflow runs tests, builds a Docker image, and publishes it to a container registry. From there, the updated image can be deployed to Kubernetes, enabling continuous delivery of updates to the ML system.
Altogether, the repository illustrates how data exploration, reproducible training pipelines, experiment tracking, containerization, monitoring, and automated deployment can be combined to form a practical end-to-end MLOps workflow.