Unsupervised Learning on Heart Attack Dataset
This project explores patient health data using unsupervised machine learning techniques in order to discover natural groupings of individuals based on medical indicators related to heart attack risk. Instead of predicting a predefined label, the analysis focuses on identifying hidden structure within the dataset, allowing patterns in patient profiles to emerge directly from the data.
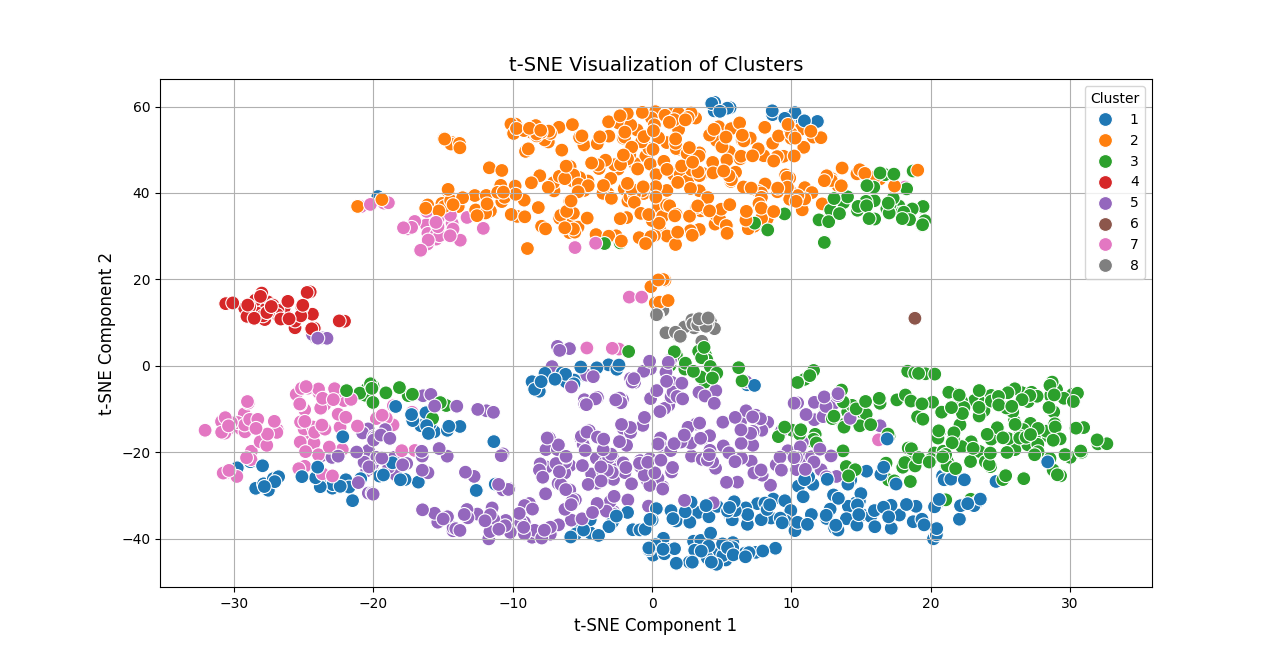
Two clustering approaches are implemented: k-means clustering and hierarchical clustering. Dimensionality reduction techniques including Principal Component Analysis (PCA) and t-SNE are used to visualize high-dimensional medical features in lower dimensions, making cluster separation interpretable. The workflow therefore follows a typical exploratory medical data analysis pipeline: preprocessing → clustering → visualization → interpretation.
The clustering objective is to partition patients into groups such that individuals inside the same cluster share similar clinical characteristics. For k-means, the algorithm minimizes within-cluster variance:
$$ J = \sum_{i=1}^{k} \sum_{x \in C_i} |x - \mu_i|^2 $$
where $C_i$ represents a cluster and $\mu_i$ its centroid.
Hierarchical clustering instead builds a tree-structured representation (dendrogram) by iteratively merging the closest groups based on distance metrics. This allows analysis at multiple granularity levels, revealing both broad risk categories and finer patient subtypes.
The resulting clusters highlight different health profiles that may correspond to varying cardiovascular risk patterns. Such grouping can assist in:
- identifying high-risk patient subpopulations
- understanding heterogeneity in medical indicators
- supporting preventive healthcare strategies
- guiding further clinical investigation
Overall, the project demonstrates how unsupervised learning can provide meaningful medical insights without requiring labeled outcomes, emphasizing its usefulness for exploratory healthcare analytics and risk stratification.