Important⚠️: Please read the Legal Notice and Data Usage section before using this dataset.
This project collects publicly available job listing data for educational and non-commercial research purposes.
Users and visitors of this project are encouraged to review the Legal Notice and Data Usage section below for important information regarding attribution, data usage conditions, and compliance with the source website’s terms.
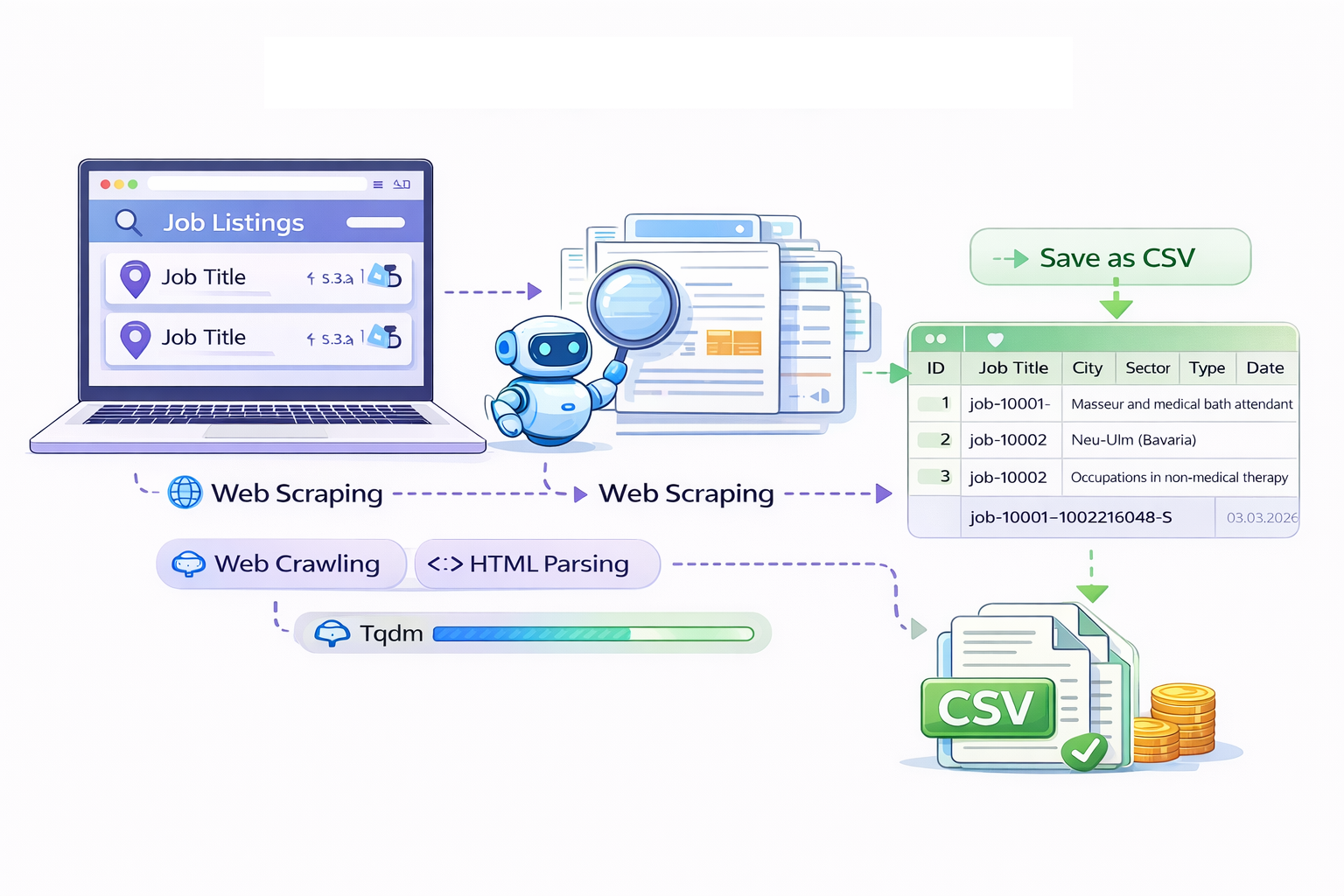
Collecting data from the internet is a fundamental step in many data science workflows. Two common approaches used for this purpose are web scraping and social media data collection. Web scraping refers to the automated extraction of information from websites using specialized programs or scripts known as web scrapers. Instead of manually copying information from multiple web pages, a scraper can automatically retrieve and structure large amounts of data.
Web scraping is particularly useful when information is distributed across many pages of a website. For example, organizations may collect data about product prices, hotel availability, or job listings across multiple platforms to analyze trends and make informed decisions. By automating the collection process, web scraping significantly reduces manual effort while enabling large-scale data analysis.
In this project, web scraping techniques were used to collect job listings from the Make it in Germany job portal, enabling the creation of a structured dataset of employment opportunities across Germany. The collected data can then be analyzed, filtered, and processed to support more efficient job discovery and labor market analysis.
To build a structured dataset of job opportunities, a Python-based web scraping pipeline was developed to collect listings from the Make it in Germany. The goal was to automatically gather relevant job information from all available listing pages and store it in a structured format for later analysis.
The scraper extracts the following information for each job posting:
- Job ID
- Job Title
- City (Place of Work)
- Sector
- Job Type (e.g., salaried employment)
- Online Since (date posted)
- URL to the job detail page
All extracted records are written to a CSV file, which can later be converted into Excel or other formats for analysis.
Approach and Methodology
The website organizes job listings across over 1,100 pages, with roughly 20 job postings per page. To gather the full dataset, the scraper performs two main operations:
1. Web Crawling
The script iterates through the paginated listing pages to retrieve the HTML content of each page.
Example:
python sc.py --out jobs.csv
This command attempts to scrape all pages from 1 to 1155.
2. HTML Parsing
Once a page is downloaded, the script parses the HTML structure and extracts job information from each job card.
Typical HTML elements used include:
<h3>for the job title<span class="element">for sector, city, and employment type<time>for the posting date<a>for the job detail link
Each job entry is converted into a row in the CSV file.
Initial Testing
Because the full dataset contains thousands of entries, the scraper was first tested on a smaller subset of pages to ensure the extraction logic worked correctly.
Example command:
python sc.py --out jobs.csv --start-page 200 --end-page 230
This scraped pages 200–230, producing several hundred job records.
Testing smaller page ranges helps verify:
- correct HTML parsing
- correct data extraction
- correct CSV formatting
- stable network behavior
Handling Rate Limiting
While scraping a large number of pages, the website may temporarily block requests if they arrive too quickly. In such cases the terminal may display an error like:
429 Client Error: Too Many Requests
Example terminal output:
RuntimeError: Failed to fetch page 50 after 5 retries:
429 Client Error: Too Many Requests
This happens because many websites limit how frequently automated requests can be made.
To address this, a delay between requests was added to the scraper.
Example:
python sc.py --out jobs.csv --sleep 3
This instructs the scraper to wait 3 seconds between page requests.
If rate limiting still occurs, increasing the delay can help:
python sc.py --out jobs.csv --sleep 5
Resuming a Scrape
If the scraper stops due to a network interruption or rate limiting, the process does not need to restart from the beginning.
Instead, scraping can resume from the last page processed.
Example:
python sc.py --out jobs.csv --start-page 50 --sleep 5
Because the script deduplicates entries using the job ID, previously scraped jobs will not be duplicated in the CSV file.
Example Workflow
A full scraping session may follow these steps:
- Test the scraper on a few pages:
python sc.py --out jobs.csv --max-pages 5
- Scrape the first portion of the dataset:
python sc.py --out jobs.csv --start-page 1 --end-page 200 --sleep 3
- Continue scraping remaining pages:
python sc.py --out jobs.csv --start-page 200 --sleep 5
- Repeat until all pages are processed.
Resulting Dataset
The final dataset contains approximately:
- 1,155 listing pages
- ~20 jobs per page
- ~23,000 total job records
Example CSV structure:
| job_id | job_title | city | sector | job_type | online_since | url |
|---|---|---|---|---|---|---|
This dataset can be opened directly in spreadsheet software or converted into Excel for easier exploration.
Legal Notice and Data Usage
This project collects publicly available job listing data from the website Make it in Germany, an information portal operated by the Federal Ministry for Economic Affairs and Climate Action of the Germany.
All data used in this project originates from publicly accessible pages of the Make it in Germany job listings portal. The scraper collects only structured metadata related to job postings (such as job title, location, sector, and posting date) and does not reproduce or modify full articles or protected editorial content.
According to the website’s published terms:
“Articles and contributions available at make-it-in-germany.com may be used free of charge and in unaltered form for non-commercial and journalistic/editorial purposes with the source clearly cited.”
Source: Make it in Germany – Legal Notice and Terms of Use https://www.make-it-in-germany.com
In accordance with these terms:
- The data collected in this project is used solely for educational, research, and analytical purposes.
- The project does not use the data for commercial purposes.
- The original source of the data is clearly cited.
- The scraping process respects the website’s robots.txt rules and includes delays between requests to avoid excessive server load.
Visitors and users of this project or website are informed that the dataset originates from publicly available information provided by Make it in Germany and remains subject to the copyright and usage policies of the original source.
This project is an independent academic exercise and is not affiliated with, endorsed by, or officially connected to the Federal Ministry for Economic Affairs and Climate Action or the Make it in Germany portal.
If the operators of the source website request removal or modification of the collected data, the dataset and related materials will be updated or removed accordingly.
The dataset created in this project does not contain personal data. Only publicly available job listing metadata (such as job title, location, and posting date) is collected. No user information, cookies, tracking data, or personal identifiers are collected or stored. The project therefore does not process personal data within the meaning of the General Data Protection Regulation (GDPR).
Future Work
The collected dataset provides a foundation for several possible data science and analytics extensions. These may include:
- data cleaning and normalization of job categories and locations
- exploratory labor market analysis across German regions
- visualization of job demand by sector or location
- time-series analysis of job postings
- development of filtering tools to help users explore relevant job opportunities
Any further analysis or tools developed using this dataset will continue to respect the non-commercial and attribution requirements of the original data source.